I was starting to wonder where an upset was going to come from.
The first eight games of this Rugby World Cup have gone pretty much to script, with results falling in line with World Rugby’s rankings, and margins of victory being corresponding well with predictions. And then Fiji v Uruguay happened.
As I removed the dust from my eye following Juan Manuel Gaminaral’s beautiful post-match interview, I wondered where this match would sit in the canon of World Cup upsets, with commentators and social media calling it “one of the biggest upsets ever”. My prediction, in line with others, had been a 27-point win for Fiji, giving Uruguay only a 5% chance of victory, as per the graphic below.
My now hilariously debunked prediction of the Fiji v Uruguay match.
To track the quality of my predictions, I’ve been plotting how the results from this tournament sit against my prediction curve on the chart below in black. I’ve also plotted the results from 2003-2015 in white to provide context. Results in the blue zone (above my trend line) indicate winning margins that were was higher than expected. In the grey zone, the higher ranked team still won, but by less than expected. Results in the orange zone represent upsets. The further to the right a data point is, the bigger the discrepancy in team strength. Today’s Fiji v Uruguay result is marked in blue. If you want to see how my predictions work, you can read about it here.
White: Matches 2003 – 2015
Black: First eight matches 2019
Blue: Fiji v Uruguay 2019
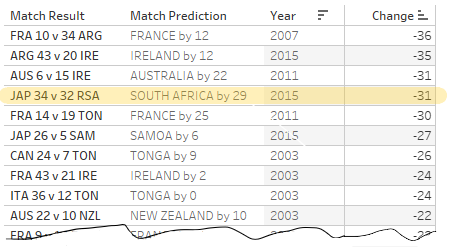
Uruguay’s victory is the second right-most upset, meaning that of all of the upsets in the data-set, this game had the second-highest discrepancy in strength between the two teams. The match with the highest? Japan v South Africa in 2015. Put in rugby terms, my model would have expected South Africa to have been better than Japan by 29 points, while today Fiji were expected to be better than Uruguay by 27.
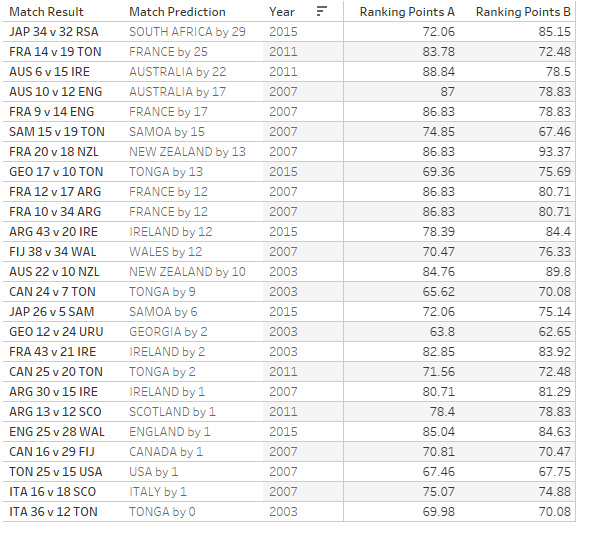
The table below shows all the RWC upsets since 2003, in descending order of the expected winning margin, where today’s match appears second.
Rugby World Cup Upsets 2003-2015, ranked in order of expected winning margin.
We could therefore conclude that Uruguay’s wonderful, tournament-alighting victory is the second biggest upset in the history of the World Cup*, just ahead of Tonga’s defeat of France in 2011.
But doesn’t this all rather miss the point? By reducing matches to a single number or a ranked list, we strip them of the context that gives them meaning. While it is valuable to take a temperature check which can protect us from overreacting in an age of hot takes, I’m not sure I’d be comfortable saying that today was a bigger, or less big, or indeed better or worse upset than Japan v South Africa.
For me, it’s the emotions that days like today invoke that make them memorable. So can we say that this was the biggest giant felling in all World Cup history? No. But have I ever cried while listening to a post match interview before? Also no.
Finally, the Uruguayan captain didn’t let his speech pass without recognising the people of Kamaishi, whose painful, inspiring story is outlined beautifully here. If you haven’t read it already, you really should.
* at least since the rankings were first published in 2003, from which my analyses are derived.
Japan’s defeat of South Africa during the 2015 Rugby World Cup was so memorable that they’ve made a film about it. A proper one. For cinemas and everything. It’s widely acknowledged as “one of the greatest shocks in the history of the tournament”, but just how big a shock was it? Could it have been anticipated? And what are the chances of it happening again if the two sides meet in the knockout stages of the 2019 tournament?
In my last post I made the case that the World Rugby Rankings represent a useful (if imperfect) proxy for the relative strength of any two teams, and can be used to contextualise performances. With a small amount of manipulation, we can begin to understand the likelihood of Japan’s victory, and by extending this approach we can assess likely outcomes of future matches, and even entire tournaments.
As per my previous post, I took the results from the four previous World Cups, plotted the points differences from each match against the corresponding difference in world ranking points, and then plotted a trend line through the data. I’ve used a curved line because it fits the data better than a straight line, and because it is pragmatically sensible: tightly ranked teams tend to result in close matches, while large ranking differences tend to mean someone’s in for a hiding.
Data from all RWC matches, 2003 – 2015.
Difference in ranking points = Difference in ranking points between the two teams in a given match.
Points difference = Highest ranked team’s score – Lower ranked team’s score in a given match.Trend line: Predicted Points Difference = (0.034 * [Difference in Ranking Points]^2) +(1.74 *[Difference in Ranking Points] ).
The trend line represents the points difference we would expect in a match between two teams given their relative difference in ranking points. The data above this line represent matches where the higher-ranked team performed better than expected. Conversely, the data below the line illustrate where the higher-ranked team performed less well than expected. Finally, the data below the horizontal axis represent upsets, where the lower ranked team won.
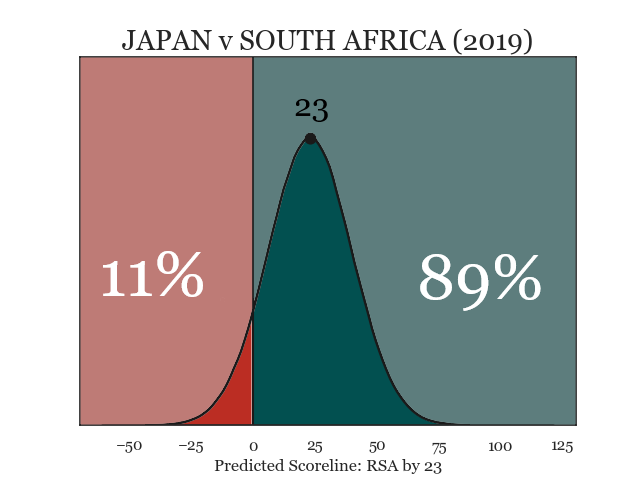
At the start of the 2015 RWC, South Africa had 13.09 more ranking points than Japan of (85.15 – 72.06). Reading off our trend line, we would therefore have expected the Springboks to beat Japan by about 29 points. If we take all of the World Cup upsets since 2003 and compare them similarly, this is indeed the largest scale of upset.
Those of you of a morbid disposition might like to hunt down your own personal heartbreak from the table below, where I’ve listed all of the upsets ranked from biggest to smallest.
Sides coached by Eddie Jones have posted notable victories in three of the matches in this list.
A more instructive approach is to assess the prediction error of each match, comparing the actual match points difference with what was predicted. If we sort our table by this metric, Japan v South Africa (2015) is actually only the fourth most remarkable reversal since 2003, behind France v Argentina (2011, Bronze medal match), Argentina v Ireland (2015, QF) and Ireland v Australia (2011, Pool stage).
Japan vs South Africa in 2015 is only the fourth biggest upset since 2003, in terms of difference between predicted and actual scoreline.
What were the chances of that happening?
[Authors note: From here on in, I’m going into more methodological detail than I normally would. I’m aware that this won’t be of interest to everyone but I want to be clear about where the numbers in other posts come from. I think transparency is important in prediction, and want people to know what method I’ve employed when they’re interpreting any predictions I make. Budding analysts might find the approach useful in their development, and equally readers might well share superior approaches].
If we look at the differences between our match predictions and actual points differences for all matches, not just the upsets, we start to do some pretty cool stuff. And by “cool” I mean of course “deeply uncool to most people, but potentially interesting to some.”
Plotting all of these prediction errors in a histogram (below), we can see that the data is more or less normally distributed around zero (which means there’s not a systematic bias in the model – this is good), and has a certain amount of spread. This is our prediction uncertainty. I’ve used the same colour coding as before – all results with a negative prediction error represent where the higher ranked team performs less well than expected. In some cases (but not all) this results in an upset.
Differences between predicted score-lines and actual score-lines from RWC 2003-2015.
If we design a population of random numbers such that it replicates the characteristics of this data set, we can create a data-set of likely outcomes for future matches. All we do here is take numbers from our artificial population (mean = 0, SD = 17), and add it to our points difference predicted by our trend line for that match up. Repeating this process many times for a match, we get a realistic distribution of possible match results around our predicted score-line.
The proportion of predicted wins and losses for each team in a match will then vary according to this distribution shape and the distance of its mid-point from zero. We can calculate the chance of victory for either side by simply counting all the occurrences either side of zero, and divided those numbers by the number of iterations. For reference, I used 1,000,000 iterations (below that my results weren’t that repeatable from run to run).
Applying this approach to Japan v South Africa (RWC 2015), we get a distribution of possible results around a likely scoreline of South Africa by 29. Approximately 5% of simulated results differences have negative points differences, in other words, giving Japan a 5% (or 1 in 20) chance of victory. While this is definitely heavily weighted in South Africa’s favour, it’s considerably better than the “this is never going to happen” chance I was still giving Japan at half-time.
Distribution of match simulation results.
Prediction Time
We can, of course, use exactly the same method for prediction. If Japan were to meet South Africa in a re-run of this game, in the quarter finals of the 2019 RWC (which is not that fantastical a proposition), today’s World Rugby ranking points give Japan an improved chance of staging an upset. Comparing the two visualisations, we can see that South Africa’s most likely winning margin has reduced from 29 to 23, but also the distribution has shifted in favour of Japan. This means, a higher proportion of simulated matches result in a Japanese victory (11%), and the chance of an upset (assuming this match were played) has improved from a 20-1 shot, to about 9-1.
Simulation results for Japan v South Africa, if they were to meet in the 2019 Rugby World Cup.
Now, none of this accounts for Japan’s (presumed) home advantage, nor does it factor in the Bokke being far less likely to underestimate the Brave Blossoms a second time around. What it does mean though, is that the gap between the two nations has narrowed considerably since that memorable day in Brighton.
Anyway, this is all very good, and hopefully of interest to some. Lots of people expand it to construct simulations of entire tournaments, using the fixture list and draw to run tens or hundreds of thousands of iterations of the tournament. Adding up the outcome stats gives the relative likelihood of various outcomes (champion, semi-finalist, pool winner, etc). While this is entertaining, for me the power is in its provision of a base-line from which we can explore other effects.
A note of caution
To round this out I want to highlight the inherent assumptions in my approach, and what that means for interpreting the results.
That the underlying model accurately represents each competitor nation. We have previously established that the rankings provide a reasonably representative generic model of outcome v relative team strength, with a certain level of variance. However, France have a reputation for being unpredictable. Meanwhile Argentina might reasonably claim the consistent over-performers. If these and other team specific effects are present, they are not factored into this approach, and the predictions are weaker for it.
That home advantage isn’t a factor. Is it a benefit? Is it a disadvantage? Likely different for any given team. Either way, it isn’t accounted for here. Maybe one to explore further in another post.
That what happened before predicts what happens next. The data set we have used here is at a minimum four years old. A quarter of the data-set is sixteen years old. In that time, squads, players, coaches and even the lawsthemselves have changed, many times over. It is entirely possible that we’ve developed a model on a set of data that no longer reflects the nature of the game.
What this all means (and this applies for interpreting any data) is: while you shouldn’t accept my results as fact, you might find them a useful input to put alongside your own knowledge, and knowing their limitations will make you better able to do so.
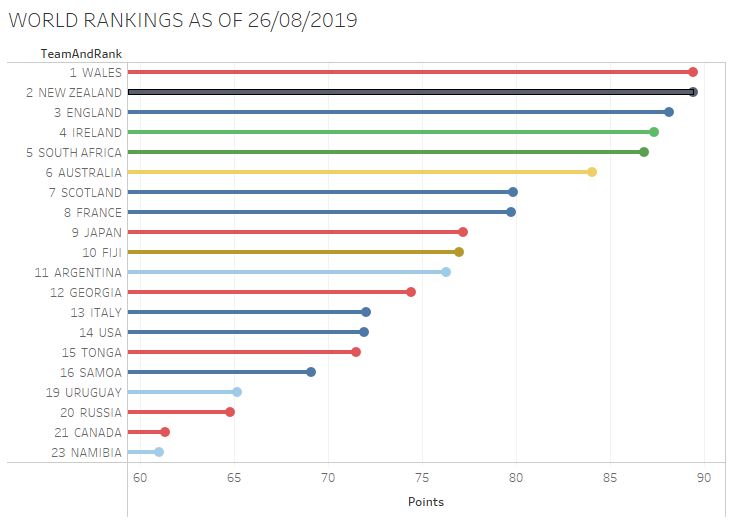
World Rankings as 28/9/2019 – Downloaded From World Rugby
It would be fair to say the World Rugby rankings have been getting some attention in the last few weeks. Wales (potentially briefly) ended New Zealand’s near decade long run as the Best Rugby Team in all the World, and a lot of people have been getting quite sniffy about it.
With Ireland, England, Wales and New Zealand all potential holders of the coveted-but-apparently-not-coveted-because-the-rankings-are-meaningless number one spot during August, considerable shade has been cast on the validity of the rankings, not least from World Rugby Vice President Agustin Pichot, who this week called the rankings “ridiculous”. Coincidentally, at the time of writing Argentina are ranked 11th in the World.
Because I like this sort of thing, I’ve been exploring how the historic rankings (from immediately prior to previous editions of World Cups) have stacked up against actual tournament and match results, to tease out if there is value to be had in them, and what this might tell us about likely outcomes of the 2019 RWC. As the rankings were first published in 2003, I’ve concentrated on the 2003, 2007, 2011 and 2015 tournaments.
Over the next few weeks I’ll be sharing how well the rankings have previously predicted tournaments and matches, what they can tell us about upsets, and how today’s can be used to predict likely outcomes of the 2019 Rugby World Cup. I might even put my head on the block and make some predictions.
“All models are wrong but some models are useful.”
– George E. P. Box in Statistical Control: By Monitoring and Feedback Adjustment
Contrary to Pichot’s opinions, when compared to actual World Cup performance, the pre-tournament rankings have proven a reliable barometer of the general world order since they were introduced in 2003. The 2003, 2011 and 2015 tournaments were all won by the team ranked number 1 at the outset (England, New Zealand, New Zealand respectively). Only the 2007 edition differed, with South Africa beginning the tournament ranked 4th.
At the individual match level, the rankings are impressively powerful indicators of likely match outcomes. Even without accounting for home advantage, the higher ranked team won 86% of world cup matches, consisting of 165 victories, two draws (Japan v Canada on both occasions; 2007 and 2011) and 25 upsets (13%).
Breaking the data down further and looking at individual tournaments, the rankings’ prediction rate is also consistently good.
While 2007 stands out here with more than twice the number of upsets than other tournaments (which is likely to be consistent with most people’s memories), its number of successful predictions still compares favourably to the FIFA official rankings ahead of the 2018 Football World Cup, which correctly predicted 59% of results (38 of 64 matches going to form, nine draws, twenty seven upsets).
The story is similar at pool stage, where outcomes are again strongly explained by pre-tournament ranking positions, and expected progression to the knockout stage is generally unaffected by any difference between actual and expected position happening elsewhere in the pools.
Pre-tournament rank vs pool stage outcomes.
In 2003, the pool winners and runners up went exactly to form, with all of the expected teams qualifying, and as winners / runners up as expected. In 2011 and 2015, only one team made it out of the groups “unexpectedly”, and in both cases at the expense of a team ranked marginally above them. 2011 also featured Australia and Ireland swapping positions as winners and runners up, but nevertheless both qualified for the knockout stages as expected.
2007, again, was a different story, with the high number of upsets significantly altering the outcomes of several pools. Fiji and Argentina in particular significantly out-performed their rank, and all pools saw a final order that was not predicted by their rankings.
So far so superficial. Where the ranking system becomes really interesting is when we start to explore the ranking points rather than the ranking positions, and compare these with actual score-lines. In the chart below I’ve plotted the difference in ranking points (highest ranked – lowest ranked) of two teams against the points difference in each match. A negative points difference means the lower ranked team won, constituting an upset.
All World Cup Matches from 2003, 2007, 2011 and 2015. The line of best fit estimates that a difference of 1 ranking point difference is worth an expected 2.4 points in a match (Rsq 75%), not accounting for home advantage.
Here we can see a strong relationship between these two factors (within reasonable bounds of uncertainty), which gives us a sense of how the ranking model can outline the relative strength of any two teams, regardless of whether they’ve recently played each other (which, after all, is the whole point). The linear trend plotted on this chart (and there are certainly more sophisticated approaches) equates to about 2.4 match points for every ranking point difference between the two teams. To put this into context, at the time of writing New Zealand and Wales are separated by an incredibly small margin in real match terms, worth about 0.07 points, or roughly 2% of a drop goal.
So can we trust them or not?
Yes. We can trust them. Just not blindly. While they’re definitely informative, we need to consider how we look at them. While the rank positions are in themselves nice accolades, the ranking points (and in particular relative difference between the points of two teams) are far more useful in understanding the relative strength of different teams. But it’s all the same model, and while it’s not perfect, it’s certainly not ridiculous.
In my next post, I’ll be looking at how we can take this a bit further to try and understand the probabilities of match outcomes, and apply a bit of context to the likelihood of some famous upsets.